The CoNaLa data was mined using a scalable, language-agnostic approach for mining parallel corpora of source code and natural language from Stack Overflow.
Automatic Mining
The key idea behind the method, described in detail in our MSR 2018 paper and this presentation slides, is to learn semantic correspondence features between the natural language and code using neural network models for machine translation, which can calculate bidirectional conditional probabilities of the code given the natural language and vice-versa of the natural language given the code.
Our approach has two components:
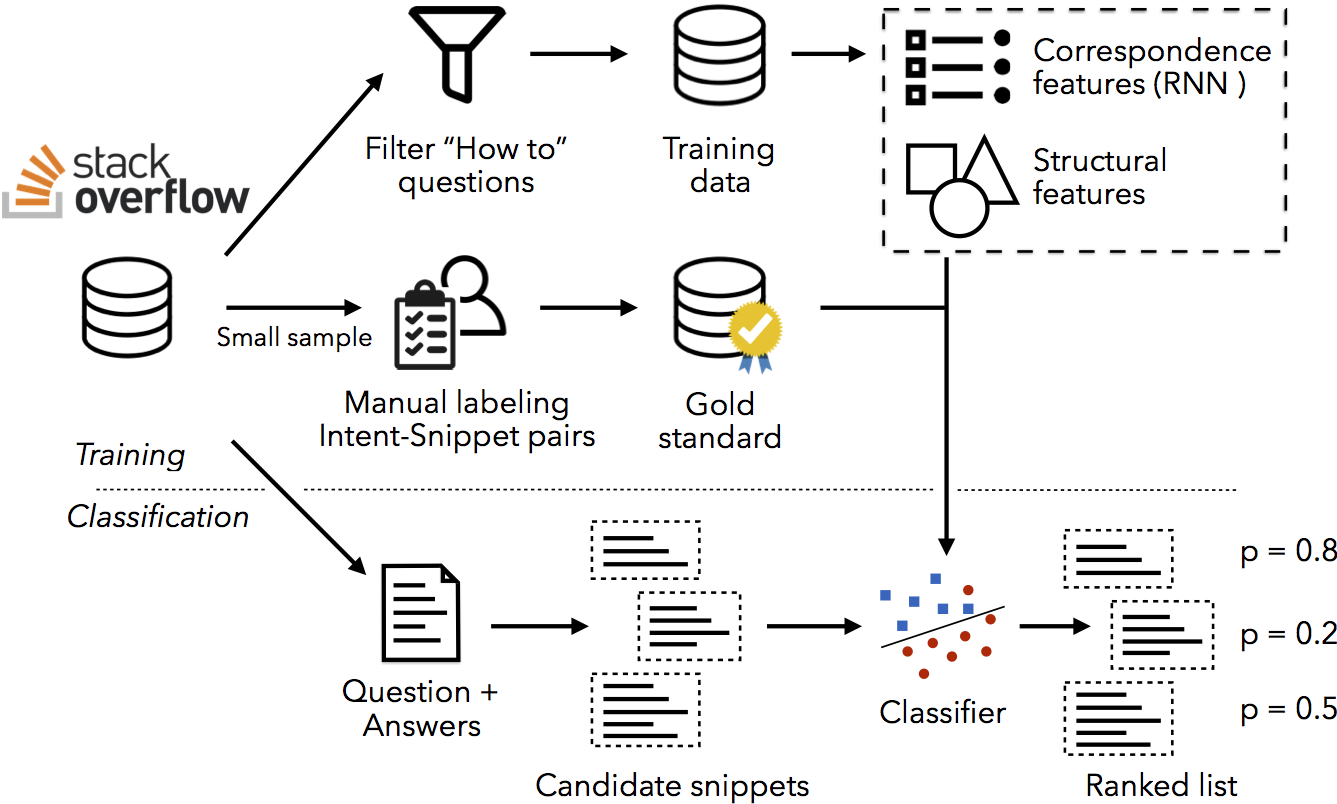
- An offline training procedure that learns a classifier to detect “good” pairs of natural language and code snippets on Stack Overflow, using only a small amount of labeled data.
- An online mining algorithm that can extract a ranked list of pairs of natural language and code from a Stack Overflow page or the Stack Overflow data dump.
You can find the training/evaluation code to reproduce the evaluation results in our MSR paper here.
Human-in-loop Quality Improvement

We aim improved the performance of the mining model using iterative human feedback. Specifically, we ask professional programmers to annotate the top-ranked predictions given by the model. And use the annotated results to re-train the model.